La haute disponibilité
La Haute Disponibilité
Statut de ce mémo
Ce document étudie les infrastructures et les différents types et méthodes de haute disponibilité dans un environnement donné. Il présente aussi les différentes solutions en termes logiciels et matériels afin de parvenir à une haute disponibilité. Ce document est une documentation ouverte.
Notice de droit
Ce document est sous licence libre : The GNU Free Documentation License.
Ce document peut-être copié et distribué sans restriction aucune.
Pour de plus amples informations, veuillez vous reporter sur cette page.
Auteur : Lealinux
Introduction
Dans le monde du clustering il existe 2 types de clusters : le cluster de calcul et le cluster de haute disponibilité. La solution qui nous intéresse est celle de la haute disponibilité.
Dans une architecture à haut risque où les services doivent être disponibles 24 heures sur 24, 7 jours sur 7, une solution devrait être en mesure d'assurer cette disponibilité. Cette solution est le "High Availbility" autrement dit "Haute disponibilité".
Le cluster de haute disponibilité est un ensemble de serveurs physiques, au nombre minimum de deux, afin d'obtenir une activité de services par tous temps, en toutes conditions, de l'ordre du 99.99% [#note1 (1)].
La haute disponibilité possède deux grands axes : La disponibilité des services et la disponibilité des données.
I) La disponibilité des services
Dans l'introduction, vous avez sûrement constaté que je mentionne deux serveurs au minimum. Pourquoi ce minimum ? Tout simplement parce qu'un service interrompu ne veut pas dire que le serveur soit toujours là. Quand un service n'est plus disponible, il ne suffit pas de détecter la panne en elle-même et de redémarrer le service en question, car le problème pourrait être beaucoup plus grave : une indisponibilité de la part du système entier, voire de la machine (problème matériel). C'est pour cela que le deuxième serveur est indispensable.
Pour en revenir à la disponibilité de services, son principe est simple : un service, quelle que soit sa machine de référence [#note2 (2)] ou les données dont il dispose, doit toujours répondre aux clients qui en font la demande. C'est-à-dire que peu importe le serveur qui répond, lorsqu'un client arrive, le service demandé doit satisfaire la demande.
Le serveur répondant est l'un des serveurs du cluster qui est (encore ?) en activité. Dans le cas d'un cluster en haute disponibilité sans load balancing (reportez-vous au chapitre "Load Balancing pour en savoir plus), le serveur maître répond à toutes les requêtes sauf si celui-ci est indisponible. Dans ce cas, c'est le ou l'un des serveurs esclaves qui répond.
Pour de la haute disponibilité de services, deux types de techniques existent : Le FailOver Services et le Linux Virtual Server.
Nous allons commencer par étudier le FailOver Services.
A - Le FailOver Services (FOS)
Le failover services est un processus de monitoring et de reprise de services pour seulement deux machines : Le serveur maître et le serveur esclave, chacun surveillant l'autre sur deux canaux et types de connectiques différents. Dans la plupart des cas, les deux types de liaisons sont de l'ordre du réseau RJ45 en utilisant le protocole TCP/IP et du câble série branché directement sur les deux machines [#note3 (3)]. Ces précautions évitent que l'un des serveurs identifie son "compagnon" comme inaccessible alors qu'il n'y a qu'un problème de congestion de réseau ou bien un problème de branchement momentané sur les câbles.
Le FailOver Services peut vérifier tout services utilisant le protocole TCP/IP et commander l'arrêt ou le démarrage de n'importe quels scripts. Ce dernier contrôle aussi l'état réseau des machines : en d'autre terme, le contrôle de l'IP de la machine.
FOS utilise un principe très simple mais à la fois très astucieux dans le changement de serveur "répondant". Il utilise l'IP Aliasing ([#appendiceA Appendice A]). L'IP Aliasing permet de définir une interface réseau avec plusieurs adresses IP différentes.
Le serveur maître et le serveur esclave possèdent tous deux une adresse IP du même sous-réseau (disons 10.10.11.1 pour le maître et 10.10.11.2 pour l'esclave). L'astuce vient du fait que lorsque le client fait appel à un serveur, il interpelle un serveur possédant une adresse IP Aliasée, c'est-à-dire qu'il n'appelle pas la machine possédant l'adresse IP 10.10.11.1 ou 10.10.11.2 mais disons par exemple 192.168.10.200. Cette adresse IP ne sera pas définie comme IP principale mais comme IP Aliasing. Ainsi lorsque le serveur maître tombe, l'adresse aliasée est redéfinie autre part.
Exemple :

Lorsque le serveur maître n'a plus de moyen de satisfaire les demandes, le FailOver Services destitue l'IP Aliasé du serveur maître pour le réattribuer sur la machine esclave. (En fait, il désactive l'adresse IP sur l'un pour la réactiver sur l'autre)

Ce procédé est à la fois simple et efficace.
Lorsque le serveur maître peut de nouveau répondre aux requêtes (détecté grâce à la première voie et attesté par la deuxième voie), FailOver désactive l'IP Aliasé de l'esclave et la réactive sur le serveur maître.
Pour que ce type de haute disponibilité fonctionne, il faut bien sûr que la machine esclave possède les mêmes services que son homologue maitre. Sinon la haute disponibilité ne fonctionnera pas.
B - Linux Virtual Server
Le Linux Virtual Server effectue le même travail que son homologue FOS mais avec un procédé légèrement différent. En effet, LVS s'appuie sur une architecture de Load Balancer et d'un ensemble de serveurs. Ce qu'il est interessant de voir, c'est que les études des trois cas de Haute disponibilité de services (FOS,LVS,LB) sont complèmentaires pour assurer un système extrêmement performant. Ainsi Linux Virtual Server peut très bien intégrer un procédé FailOver dans ses serveurs de contrôle de Load Balacing.
Exemple d'un cluster LVS simple :

Le procédé qu'utilise le redirecteur LVS est simple, grâce à l'un des quatre algorithmes de load balacing. Il redirige les paquets vers les serveurs appropriés en utilisant l'une des quatres méthodes de routage (voir plus bas, 1.C)
Le redirecteur LVS conserve les information quant à l'état des différents serveurs de son cluster et se charge de répartir la charge parmi les serveurs en fonctionnement. Si un serveur devient indisponible, le redirecteur LVS dirige alors les requetes vers un (des) autre(s) serveur(s) du cluster jusqu'à ce que le serveur défaillant soit à nouveau disponible.
LVS supporte différentes méthodes de routage : la translation d'adresse de réseau (Network Address Translation [NAT]), l'encapsulation d'IP (IP Encapsultation [Tunneling]) et le routage direct.
La translation d'adresse est utilisée spécifiquement pour un réseau privé. Dans cette méthode de routage, toutes les requêtes passent par le routeur principal (Redirecteur LVS). L'ensemble des paquets transitant sur le redirecteur sont réécrits puis renvoyés vers un serveur, ou le client. De cette façon, le réseau privé contenant les serveurs est masqueradé pour les requêtes des clients. Le gros désavantage de ce type de routage est le goulot d'étranglement qui peut se créer au niveau du Redirecteur. En effet, pour une solution d'une vingtaine ou plus de serveurs, le routeur est surchargé de demandes et ne peut plus traiter les informations [#note5 (5)]. De plus les serveurs doivent être physiquement dans le même réseau pour que le Redirecteur puisse agir correctement sur le routage.
Si votre souci est celui du lien géographique des serveurs, l'encapsulation peut être une solution. Le procédé ressemble, au début, à la translation d'adresse, si ce n'est que le redirecteur ne traite que les requêtes du client aux serveurs (requêtes entrantes). Les requêtes sortantes sont traitées du serveur au client directement sans passer par le redirecteur. Ainsi les différents serveurs peuvent se trouver n'importe où géographiquement parlant. Avant d'assigner un travail à un serveur, le redirecteur encapsule l'adresse IP du client à l'intérieur de l'adresse du serveur.
L'inconvénient de cette solution peut venir d'une certaine paranoïa du fait que nous envoyons une requête vers un serveur et c'est un autre qui nous répond. [#note6 (6)]

Note de l'auteur: Ne prétez pas attention à la légende, les mentions sont inversées
Si vous souhaitez utiliser ce principe mais au sein de votre réseau privé, le routage direct est ce qu'il vous faut. Le routage direct ressemble à peu de chose à la méthode d'encapsulation d'IP, si ce n'est qu'une troisième couche existe entre le client et les routeurs et que le réseau n'est plus public mais privé. Les requêtes sortantes (réponses) vont directement du serveur final au client demandeur. Cependant, les requêtes entrantes passent par deux "filtres" de routeur. Le premier est un simple routeur qui dispatche les requêtes sur une multitude de clusters de routeurs et de routeurs de sauvegarde. A partir de là, la méthode est la même que pour la méthode d'encapsulation d'IP.

Note de l'auteur: Ne prétez pas attention à la légende, les mentions sont inversées
Il existe une dernière méthode de routage, mais celle-ci est implantée dans... le DNS. Je vous préviens de suite, cette méthode ressemble plus à du Load Balacing sans contrôle, dans le sens où le DNS ne sait absolument pas si le serveur sous-jacent est en pleine possession de ses activités. La mise en place est relativement simple. Dans le DNS, lors de la définition du nom de domaine, il suffit de rajouter autant de lignes que de serveurs de sauvegarde (Backup Servers) :
serveur.tld A 192.168.10.2 ; Server 1 A 192.168.10.3 ; Server 2 A 192.168.10.4 ; Server 3
Le DNS va donner aléatoirement une addresse IP.
Cette méthode de routage ne permet pas de la haute disponibilité sûre à 100%, elle permet juste de faire un semblant de Load Balacing. Cette méthode est parfois utilisée dans le système du routage direct en place au lieu du lien entre le premier routeur et l'un des clusters.
C - Algorithmes de Load Balacing
Comme je vous l'ai annoncé plus haut, il existe quatre algorithmes différents pour effectuer du Load Balancing. Le plus simple est le "Round Robin" qui consiste à distribuer le travail équitablement entre tous les serveurs. Le suivant est "Least-connexions" qui consiste à distribuer le plus de travail sur les serveurs avec le moins de connexions actives. Dans ce cas, l'IPVS enregistre les connexions actives. Le troisième algorithme, "Weighted round robin" distribue le plus de travail au serveur de grande capacité (Indiqué par l'utilisateur) et enfin le dernier, le "Weighted least-connexions" distribue le plus de travail avec le moins de connexions actives aux serveurs de grande capacité.
D - Conclusion de chapitre
Au début de ce chapitre, je vous ai cité cette phrase "Un service, quelle que soit sa machine de référence ou les données dont ils disposent, doit toujours répondre aux clients qui en fait la demande". ... "quelque soit [..] les données dont ils disposent", cette phrase a toute sont importance dans le domaine de la haute disponibilité. Dans toutes les méthodes de haute disponibilité de services, il existe un problème majeur : les données. En effet, lorsqu'un serveur primaire tombe, le serveur secondaire prend le relais. Mais ce serveur ne possède pas les données du serveur primaire. (et inversement) (notamment pour les serveurs de mail, les bases de données, etc...). Ce qui pourrait être regrettable, ce sont les coupures de données entre les deux serveurs.

C'est pour cela que l'on va étudier la haute disponibilité de données, ou le partage de données (shared data).
II) La disponibilité des données
Dans ce domaine-ci, il existe deux types de haute disponibilité de données : les données partagées et les données répliquées. Les données partagées le sont dans le domaine du réseau. Les données répliquées appartiennent à deux domaines : celui du réseau (réplication serveur à serveur) ou local (réplication disque à disque). Cependant dans tous ces domaines, un domaine est prédominant : le type de système de fichiers (filesystem). Ce domaine est très lié à celui des types de haute disponibilité de données. Certains systèmes de fichiers sont orientés réseaux (GFS, Intermezzo, DRBD, NFS [#note7 (7)], M2CS, FENRIS, Coda, LVM) ou orientés local (ReiserFS, Ext3, LinLogFS, Raid)
Voici les différents types de systèmes de fichiers répartis par domaine
A - Premières introduction sur les systèmes de fichiers
1) Lan Mirroring
DRBD [MIRRORING] Network Block Device (NBD) [MIRRORING] NFS [SHARED] CodaFS [SHARED] ODR : Online Disk Replicator [MIRRORING] ENBD : Enhanced Network Block Device [MIRRORING] Network RAID [MIRRORING]
2) Volume Managers
LVM [PARTITIONING] EVMS : Enterprise Volume Management System (émulateur lvm)[PARTITIONING]
3) FileSystem
GFS [CLUSTERING/JOURNALING] ReiserFS [JOURNALING] Ext3 [JOURNALING] JFS (IBM) [JOURNALING] XFS (SGI) [JOURNALING] FENRIS (Timponagos) [CLUSTERING] M2CS (Timponagos) [CLUSTERING] Intermezzo [CLUSTERING] LinLogFS [CLUSTERING] OCFS2 (Oracle) [CLUSTERING]
4) Autres
RAID [MIRRORING]
Avant de commencer, voici un tableau récapitulatif sur les différents modes des systèmes de fichiers.
| Nom du système de fichier | Miroir | Partage | Partitionnement | Par réseau | En local | Clustering | Journaliser |
| DRBD | X | X | X | ||||
| Network Block Device (NBD) | X | X | X | ||||
| NFS | X(a) | X | X | X(a) | |||
| Coda FS | X | X | X | X(a) | |||
| Online Disk Replicator (ODR) | X | X | X | X | |||
| Enhanced Network Block Device | X | X | X | ||||
| Network RAID | X | X | X | ||||
| LVM | X | X | X | X | X | ||
| Enterprise Volume Management | X | X | X | X | X | ||
| GFS | X | X | X | X | |||
| OCFS2 | X | X | X | X | |||
| ReiserFS | X | X | |||||
| Ext3 | X | X | |||||
| JFS | X | X | |||||
| FENRIS | ? | ? | ? | ? | ? | ? | ? |
| M2CS | ? | ? | ? | ? | ? | ? | ? |
| InterMezzo | X | ? | X | X | X | ||
| LinLogFS | X | X | X | X | |||
| RAID | X | X | X | ||||
| SAN | X(a) | X | X(?) | X | X | X(a) |
(a) Tout dépend du système de fichiers utilisé sur le serveur
Avant de passer à des exemples concrets et des méthodes d'utilisation de tous ces systèmes de fichiers, un rappel rapide s'impose. De plus, afin de ne pas se disperser pour l'instant, nous allons étudier les systèmes de fichier suivant : DRBD, NBD, NFS, GFS, ReiserFS, Ext3, InterMezzo ainsi que le Raid au niveau matériel.
B - Le Raid dans une solution de haute disponibilité.
Autant vous le dire tout de suite, le raid n'est pas une solution 100% viable dans un système de haute disponibilité. Pourquoi ? Le système devient viable si et seulement si vous êtes sûr que votre serveur ne tombera pas en panne. Le système Raid ne vous aidera que pour un secours disque, c'est-a-dire que lorsqu'un disque ne fonctionne plus correctement, un autre prend le relais. Mais au cas ou le serveur tombe entièrement, le raid ne pourra plus faire grand chose. Malgré tout, le Raid reste une solution très utile et à privilègier lorsqu'on le peut.
Le système Raid possède 6 mécanismes internes.
Mode Linéaire
Ce mécanisme utilise le deuxième disque dur si, et seulement si, le premier disque dur n'a plus assez d'espace disque.Cette solution n'a pas trop d'avantage puisque si un disque dur tombe, toutes les données du dit disque sont perdues.
Mode Raid 0
Ce mécanisme effectue une découpe des données (strip). L'ensemble des données sont dispatchées sur les deux disque durs ce qui permet une nette amélioration des performances d'entrée et sortie. Cependant, comme le mode Linéaire, ce mode n'est pas à utiliser dans un système de haute disponibilité, puisque si un disque tombe, toutes les données sont perdues.
Mode Raid 1
Ce mécanisme effectue un mirror parfait sur autant de disques qu'il y en a de disponibles.
Cette solution est généralement utilisée dans un système de haute disponibilité car il permet la redondance de données sur plusieurs disques avec une nette amélioration des performances en lecture. Par contre, les performances en écriture subissent une dégradation suite à l'écriture sur plusieurs disques. Et afin d'effectuer ces écritures, le processeur est quelques peu utilisé.
Mode Raid 0+1
Ce mécanisme est une sorte de fusion entre le Raid 0 et le Raid 1, les données sont dispatchées sur les disques durs, mais contraitrement au Mode Raid 0, si un disque dur tombe, les données peuvent toujours être récupérées. De plus les gains de performance ne se limitent plus qu'au mode lecture mais au mode écriture aussi. Le processeur, quant a lui, est quelques peu mobilisé lors d'accès lecture/écriture.
Mode Raid 4
Ce mécanisme utilise 3 disques dur mininum. Ce dernier dispatche les données sur les deux disques et écrit les données supplémentaires de parité sur le troisième disque. Cette méthode permet à un disque dur de tomber sans en perdre les données. Cependant, il existe un problème au niveau de l'écriture pour les données de parité : un goulot d'étranglement sur le troisième disque. Chaque modification sur l'un des deux premiers disques oblige le troisième à écrire ou modifier ses données de parité.
Mode Raid 5
Ce mécanisme est similaire au Raid 4, si ce n'est que le problème du goulot d'étranglement n'existe plus car les informations de parité sont ecrites sur chaque disque.
Dans un système de haute disponibilité, les Raid 1, 4 et 5 sont vivement recommandés car il existe toujours un disque de remplacement.
C - Le Ext3 dans une solution de haute disponibilité
Le Ext3 est un système de fichiers journalisé. Il est le remplaçant de l'ext2. Ce système de fichiers a évolué principalement à cause des durées souvent trop longues lors d'une vérification du système de fichiers lorsque le serveur n'a pas réussi à démonter proprement les partitions (généralement après un plantage du serveur). Le grand avantage du Ext3 par rapport aux autres systèmes de fichiers est que l'on passe de l'Ext3 à l'Ext2 et inversement sans problème et sans avoir à jouer avec les différentes partitions pour garder ses données.
De plus, en paramétrant correctement son fstab, l'ext2 peut très bien interpréter l'ext3 et vice-versa. (En fait, l'Ext2 et l'Ext3 sont semblables, mis à part que l'Ext3 possède un journal. Si le kernel ne peut lire que l'ext2, il ne prendra pas en compte le journal).
D - Le ReiserFS dans une solution de haute disponibilité
Le ReiserFS est aussi un système de fichiers journalisé. Ce dernier se distingue par le fait qu'il est basé sur une notion d'arbre.
De plus, il gagne en performance pour un nombre important de fichiers dans un même répertoire et en espace pour les petits fichiers (sous d'autres filesystems, chaque fichier prend un block au minimum, tandis que le ReiserFS essaye de caser tout dans un seul si le fichier fait moins d'un block). Ce système de fichiers est efficace mais plus difficilement applicable sur un système déjà existant.
E - InterMezzo dans une solution de haute disponibilité
Le système de fichier InterMezzo est quelque peu différent de ses congénères (vus au dessus). InterMezzo permet une réplication par réseau des données. Il intégre une gestion de déconnexion (si l'un des serveurs de sauvegarde est indisponible, il sera resynchronisé plus tard) et gère l'Ext3, le ReiserFS et le XFS pour l'instant. InterMezzo s'inspire du fonctionnement de Coda (voir plus bas ou Appendice B) Très utile dans un système de haute disponibilité, son grand désavantage, c'est qu'il est encore en développement à l'heure actuelle.
F - The Network Block Device (NBD) dans une solution de haute disponibilité. (C)
Network Block Device reprend le principe d'InterMezzo et de Coda, dans le sens où il effectue une copie conforme d'un serveur à un autre serveur au moyen du réseau. A la seule différence qu'il n'utilise que Ext2 et NFS nativement.
G - Network File System (NFS) dans une solution de haute disponibilité
Le NFS procède différemment d'InterMezzo, Coda et autres NBD car il n'effectue pas une réplication de données mais plutôt un partage de données (data shared). Le système de données ne se trouve pas sur les serveurs de services mais sur un autres serveur dédié ou pas à ce travail. Le gros point noir de NFS est la sécurité : les discussions entre le serveur et son client ne sont pas protégées et les permissions laissent à désirer.
Une solution envisageable consiste soit à utiliser du Tunneling soit à utiliser directement sNFS (Secure Network File System) Cette solution est, malgré tout, recommandé dans certaines solutions de haute disponibilité.
H - Global File System (GFS) dans une solution de haute disponibilité (B)
J'ai trouvé cette définition tellement bien faite, que je vous la donne directement :
"Global File System (GFS) est un système de fichiers sous Linux permettant de partager les disques d'un cluster. GFS supporte la journalisation et la récupération de données suite à des défaillances de clients. Les noeuds de cluster GFS partagent physiquement le même stockage par le biais de la fibre optique ou des périphériques SCSI partagés. Le système de fichiers semble être local sur chaque noeud et GFS synchronise l'accès aux fichiers sur le cluster. GFS est complètement symétrique ce qui signifie que tous les noeuds sont équivalents et qu'il n'y a pas un serveur susceptible d'être un entonnoir ou un point de panne. GFS utilise un cache en lecture écriture tout en conservant la sémantique complète du système de fichiers Unix.
Tout est dit sur ce système de fichiers, mis à part que GFS s'adresse directement aux personnes ayant les moyens car la fibre d'optique ou les périphériques SCSI ne sont pas bon marché. Hormis ce problème, GFS est un atout indispensable dans une solution de haute disponibilité mais surtout dans le cadre d'un Cluster.
I - DRBD dans une solution de haute disponiblité
DRBD, comme InterMezzo et NBD, effectue un replica parfait du disque primaire sur un autre disque dur d'un serveur tiers par voie réseau. DRBD est indépendant du type de système de fichiers utilisé sur le serveur. Vous pouvez donc utiliser n'importe quel système de fichiers.
Tout comme ses congénères, DRBD propose deux types de synchronisation : partielle ou totale. La synchronisation partielle n'effectue une mise à jour du disque secondaire que dans les parties non synchronisées (si le serveur a planté par exemple, rien ne sert de refaire une copie du disque primaire). La synchronisation totale, elle, effectue une copie disque à disque complète, comme si le disque secondaire venait d'être installé.
J - SAN/NAS dans une solution de haute disponiblité
SAN (Storage Area Network) et NAS (Network Attached Storage) sont des serveurs dédiés au stockage de données. Toutefois, SAN et NAS sont différents mais complémentaires. En effet les deux types peuvent être utilisés en même temps pour un service de haute disponibilité. Le NAS se charge du réseau et SAN se charge des serveurs de données. SAN utilise un protocole SCSI tandis que NAS utilise un protocole IP.
SAN est plus une extension pour serveur alors que NAS est plus dans une optique réseau. SAN est plus rapide du fait de sa connectique alors que son homologue NAS améliore grandement le modèle de stockage. Je vous conseille pour plus d'informations, la référence sur SAN/NAS dans l'Appendix B.
Tableau de comparaison :
| NAS | SAN | |
| Réseau | Réseau déjà existant | Réseau spécialisé (Fibre Channel) |
| Fonction unité de stockage | Serveur de fichiers | Serveur de ressources de stockage |
| Protocole | Type message (NFS over TCP/IP) | Type I/O SCSI |
| Bande passante | Dépendant du type (Eth : 10-1000 Mbits/s) | Avec Fibre Channel : n * 1 Gbits/s |
| Administration | Stockage administré à travers le serveur de fichiers | Administration directe incluant l'infrastructure SAN |
K - CodaFS dans une solution de haute disponibilité
CodaFS est un système de fichiers de répartition et de distribution (un peu comme NFS) mais qui intègre des performances et des options aux tolérances de pannes et de sécurité. CodaFS permet une réplication de données, une émulation sémantique et une sécurité accrûe en utilisant les ACLs. Pour en savoir plus sur Coda, je vous conseille de lire la documentation indiqué dans [#appendiceB l'Appendice B] : CodaFS
III) De la théorie à la pratique
Dans cette partie, nous allons voir comment utiliser ces différents systèmes de fichiers (même ceux non décrits ci-dessus). Nous n'allons pas réellement passer à la pratique, mais plutôt nous en approcher à l'aide de schémas et d'exemples concrets. Les exemples décrits ci-dessous ne sont pas exhaustifs. Il existe de nombreuses possibilités de haute disponibilité à partir des ces bases.
A - Solution de Partage
Les solutions de partage sont simples : les données se trouvent sur l'un des serveurs et les autres serveurs peuvent atteindre ces mêmes données. Pour une solution de haute disponibilité, les données ne peuvent pas se trouver sur l'un des serveurs-services, tout simplement parce que les données seront indisponibles pour les autres serveurs si celui-ci tombe. C'est dans cette optique qu'un serveur est disponible uniquement pour les données. Généralement, ce type de solution combine au minimum trois serveurs : deux de services (un primaire, un de sauvegarde) et un serveur de données.

Pour ce type de partage, il n'existe, sauf erreur de ma part [#note8 (8)], que NFS, Samba (dans une certaine mesure), GFS et SAN/NAS qui permettent de faire ceci. Les données sont accessibles par les deux serveurs de services. Si l'un des deux tombe, l'autre est en mesure de lire et de continuer d'écrire sur le serveur de données.
Si le serveur de données tombe, il n'existe qu'un seul moyen : la réplication.
B - La réplication
1) La réplication en local
La réplication locale est une réplication qui s'effectue sur le serveur même et non sur un serveur tiers. Ce mode de réplication peut très bien être ajouté dans une réplication par réseau déjà existante.
Dans cette solution, le Raid est souvent utilisé. (il me semble, sauf erreur de ma part, qu'il n'existe pas d'autre mode de réplication en local. Voir peut-être le système SAN qui utilisait un protocole SCSI)

Le système Raid peut-être logiciel ou matériel. S'il est logiciel, c'est la couche applicative ou le système d'exploitation qui effectue cette réplication. S'il est matériel, c'est le système physiquement (contrôleur, carte dédiée, ...) qui effectue la réplication sur les N disques.
La solution logicielle est certes plus économique mais demande plus de ressource processeur que son homologue matériel. De plus, la solution logicielle est gérée par une couche applicative et les logiciels sont plus sujets à des problèmes, notamment les bugs, que les solutions matérielles.
Les solutions matérielles, elles, sont plus fiables mais sont plus onéreuses.
2) La réplication par réseau
Pour notre cas ci-dessus, il existe deux cas pour la réplication : de serveur-services à serveur-services ou bien de serveur-données à serveur-données.
Le premier cas est une réplication par réseau des données essentielles pour les deux serveurs. Ainsi, si le serveur de services primaire est indisponible, le serveur de sauvegarde sera parfaitement operationnel avec l'ensemble des données à sa disposition.

A son retour, la resynchonisation du serveur primaire s'effectuera immédiatement et automatiquement.
Le deuxième cas est une réplication du serveur de partages. Le principe est le même que pour les serveurs de services.

La réplication ne se fait qu'au niveau des serveurs de données. Les deux groupements de serveurs sont liés par un "lien" Heartbeat qui assure une reprise par le serveur secondaire si le primaire venait à tomber.
Il existe une autre manière d'obtenir une haute disponibilité à l'aide d'un ensemble de serveurs. Il s'agit d'une méthode utilisant le système SAN/NAS.
- Le réseau NAS : il utilise un réseau déjà existant, il n'est donc pas nécessaire d'investir énormement dans une conception réseau pour ce type de stockage.Pour des raisons de performance, il est préférable de s'approprier un sous-réseau propre pour NAS. Comme vous l'avez sûrement remarqué, plusieurs serveurs sont rattachés aux seuls serveurs NAS. Il existe un réel problème de goulot d'étranglement au point 'O'.
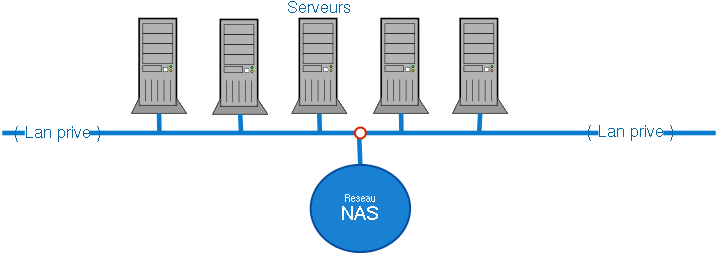
- Le réseau SAN : il utilise une connexion SCSI/Fibre Channel. Contrairement à NAS, celui-ci demande plus d'investissement pour concevoir ce type de stockage.
Même si celui est onéreux, le goulot d'étranglement n'existe pas (ou bien il faut réellement en vouloir :) - Réseau NAS/SAN : ce réseau est une fusion entre le NAS et SAN. Bon attention au schéma, il faut le comprendre :)
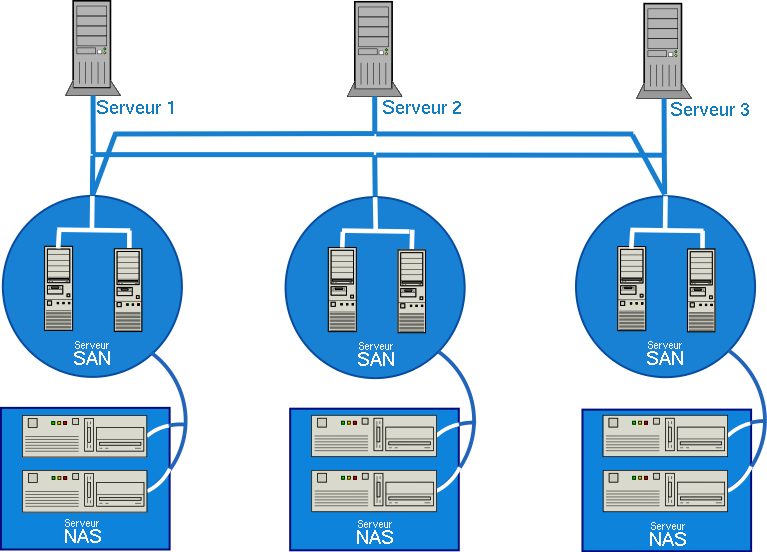
Normalement, c'est un peu plus compliqué, car les hubs/switch (non représentés) répartissent les données des serveurs vers les différents SAN qui, eux-mêmes, répartissent vers les différents Serveur NAS.


{kind=link}
III) Les exemples concret de haute disponibilité.
A l'aide des connaissances acquises ci-dessus, nous pouvez établir quelques exemples pour des services de haute disponibilité. Nous décrirons aussi les avantages et les inconvénients de chaque solution.
A. FailOverServices Simples
Nombre de machines minimum nécessaire : 2
Logiciels ou matériels nécessaires : HeartBeat + services multipliés par le nombre de serveurs.

- Avantage de cette solution : une haute disponiblité correcte pour une mise en place relativement simple.
- Inconvénient de cette solution : des données qui sont uniques entre chaque serveur, risque de perte de données notamment pour les serveurs de données (ex: smtp)
B. FailOverServices Simples avec réplication locale
Nombre de machines minimum nécessaire : 2
Logiciels ou matériels nécessaires : HeartBeat + Raid + services multipliés par le nombre de serveurs.

- Avantage de cette solution : la perte de données dûe à la perte d'un disque est résolue.
- Inconvénient de cette solution : tout comme le point FailOverServices Simples (A), les données sont uniques sur chaque serveur. Le fait d'ajouter des disques en Raid n'apporte pas véritablement d'avantage si ce n'est que les données seront effectivement bien protégées.
C. FailOverServices Simples avec réplication réseau
Nombre de machines minimum nécessaire : 2
Logiciels ou matériels nécessaires : HeartBeat + Système de fichier de réplication + les services multipliés par le nombre de serveurs.

- Avantage de cette solution : les données sont disponibles directement sur les deux serveurs en local (rapidité)
- Inconvénient de cette solution : très peu, mis à part que la réplication nécessite un bon réseau en support pour synchroniser rapidement et efficacement les données entre les serveurs.
D. FailOverServices Simples avec utilisation d'un serveur de données
Nombre de machines minimum nécessaire : 3
Logiciels ou matériels nécessaires : heartBeat + NFS (ou équivalent) + les services multipliés par le nombre de serveurs-services.

- Avantage : les données sont disponibles pour les deux serveurs en direct
- Inconvénient : aucun pour les services. Si le serveur de données tombe, aucun des serveurs n'aura accès aux données.
E. FailOverServices Simples avec utilisation d'un serveur de données "FailOveriser" réplication réseau
Nombre de machines minimum nécessaire : 4
Logiciels ou matériels nécessaires : heartBeat + NFS (ou équivalent) + Système de fichiers réplication réseau + les services multipliés par le nombre de serveurs-services.

- Avantage : les données sont disponibles pour les deux serveurs en direct et en redondance, une disponibilité accrue
- Inconvénient : aucune réplication de données en local, l'un des disques pourrait tomber.
F. FailOverServices Simples avec utilisation d'un serveur de données "FailOveriser" réplication réseau et local
Nombre de machines minimum nécessaire : 4
Logiciels ou matériels nécessaires : heartBeat + NFS (ou équivalent) + Système de fichiers réplication réseau + RAID + les services multipliés par le nombre de serveurs-services.

- Avantage : une grande disponibilité avec quatre serveurs.
- Inconvénient : si les serveurs primaires sont beaucoup solicités, ces derniers ne seront plus disponibles.
G. FailOverServices avec du LoadBalancing avec utilisation d'un ou plusieurs serveurs de données "FailOveriser" réplication réseau et local
Nombre de machines minium nécessaire : 10 (voire moins si on joue avec l'optimisation machine)
Logiciels ou matériels nécessaires : heartBeat + NFS (ou équivalent) + Système de fichiers + réplication réseau + RAID + Routeur/Switch ou tout autres logiciels qui permet de faire du routage + les services multipliés par le nombre de serveurs-services.

- Avantage : une grande disponibilité avec prise de conscience des possibilités de haute sollicitation de groupe primaire de serveurs
- Inconvénient : nécessite une infrastructure solide dûe au nombre de machines. Que se passe-t-il si le routeur tombe ? :)
Le mot de la fin
Comme vous l'avez constaté, il existe de nombreuses variantes de haute disponibilité. Je vais donc m'arrêter là car il existe autant de choix de structures réseau que de problèmes. L'infrastructure dépendra de ce que vous voulez en faire et de votre inquiétude pour la disponibilité des données et des services.
Je n'ai pas tout couvert, comme par exemple le NAS/SAN dans les exemples d'infrastructures. Tout simplement parce que les serveurs de données (voir juste au-dessus) peuvent très bien être des serveurs simples (NFS) ou bien des serveurs NAS/SAN.
Il vous suffit juste de modéliser votre réseau comme bon vous semble.
Je vous conseillerais pour autant de réfléchir sur chaque serveur (même le secondaire, du secondaire, du ..etc..) sur le moyen de le faire "tomber". Vous trouverez toujours une solution.
Par contre, ne poussez pas la haute disponibilité à l'extrême jusqu'à concevoir des centaines de réseau dispatchés sur le globe qui disposeraient d'une cinquantaine de machines juste pour être sûr que votre serveur internet ou votre serveur smtp soit disponible à toute heure.
Bonne construction...
(1) Une disponibilité de l'ordre de 100% n'est que théorique. Aucun service ne peut être disponible à 100%. Cependant lorsque l'on parle de haute disponibilité, les services s'approchent de ce chiffre, mais une panne exceptionnelle de tout ordre peut intervenir (Foudre, Feu, Apocalypse...)
(2) La machine de référence est la machine où le service est installé.
(3) Ce lien est un "lien heartbeat", il peut être de toutes formes : cable série, Ethernet, Wireless, Transmission de pensée, etc...
(4) Il est vrai que FOS et Linux Virtual Server peuvent très bien être complémentaires comme pour le cas des serveurs de Load Balacing (voir plus bas dans la section "Linux Virtual Server").
(5) Bien sûr, cela dépend de l'architecture machine, un 486 ne pourra pas être en charge d'autant de serveurs qu'un processeur plus evolué.
(6) Cela peut poser problème pour certains programmes où la sécurité est primordiale chez eux.
(7) NFS est plutôt un cas particulier car il est plus dans l'optique du partage de données.
(8) J'ai repéré quelques systèmes de fichiers spécialement pour le partage comme NFS : ClusterNFS, il me semble que c'est un patch pour le serveur NFS universel ; Network Disk Device.
Appendice A : documentation en français de l' IP Aliasing
Appendix B : une série de liens utiles :
Notes de l'auteur :
Je tiens à remercier Anne qui a pris du temps pour corriger les très nombreuses fautes de l'article original et qui a converti la documentation en HTML.
Je jure que la prochaine fois, je me relirai ;-)
@ Retour à la rubrique Administration système
Copyright
Copyright © 25/11/2002, Léalinux
| Ce document est publié sous licence Creative Commons Attribution, Partage à l'identique, Contexte non commercial 2.0 : http://creativecommons.org/licenses/by-nc-sa/2.0/fr/ |
NdA: Si vous utilisez cette documentation pour l'écriture d'un article, d'un rapport, d'une thèse, ou autres, envoyez moi un petit mail :-)
(merci à ceux qui l'ont déjà fait :-)